Goal¶
- How to split dataset
- Important dataset
- End to end training
- Metacentrum - Czech Computational Grid
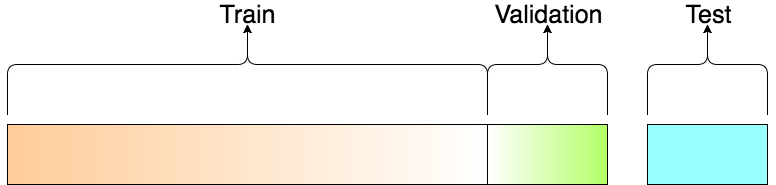
How to split dataset¶
Training Dataset¶
Training Dataset: The sample of data used to fit the model. The actual dataset that we use to train the model (weights and biases in the case of a Neural Network). The model sees and learns from this data.
Validation Dataset¶
Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
The validation set is used to evaluate a given model, but this is for frequent evaluation.
Test Dataset¶
Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
The Test dataset provides the gold standard used to evaluate the model. It is only used once a model is completely trained(using the train and validation sets).
import numpy as np
from sklearn.model_selection import train_test_split
X, y = np.arange(10).reshape((5, 2)), range(5)
X,y
(array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]]),
range(0, 5))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
X_train, X_test, y_train, y_test
(array([[4, 5],
[0, 1],
[6, 7]]),
array([[2, 3],
[8, 9]]),
[2, 0, 3],
[1, 4])
References¶
Datasets¶
MNIST¶
The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST.

References¶
- Kussul, Ernst; Baidyk, Tatiana (2004). "Improved method of handwritten digit recognition tested on MNIST database". Image and Vision Computing. 22 (12): 971–981. doi:10.1016/j.imavis.2004.03.008 .
ImageNet¶
The most highly-used subset of ImageNet is the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012-2017 image classification and localization dataset. This dataset spans 1000 object classes and contains 1,281,167 training images, 50,000 validation images and 100,000 test images. This subset is available on Kaggle.

On 30 September 2012, a convolutional neural network (CNN) called AlexNet achieved a top-5 error of 15.3% in the ImageNet 2012 Challenge, more than 10.8 percentage points lower than that of the runner up. This was made feasible due to the use of graphics processing units (GPUs) during training, an essential ingredient of the deep learning revolution. According to The Economist, "Suddenly people started to pay attention, not just within the AI community but across the technology industry as a whole."
References¶
- J. Deng, W. Dong, R. Socher, L. -J. Li, Kai Li and Li Fei-Fei, "ImageNet: A large-scale hierarchical image database," 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248-255, doi: 10.1109/CVPR.2009.5206848.
- Wikipedia: ImageNet
- Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffrey E. (June 2017). "ImageNet classification with deep convolutional neural networks" (PDF). Communications of the ACM. 60 (6): 84–90. doi:10.1145/3065386. ISSN 0001-0782. S2CID 195908774. Retrieved 24 May 2017.
- Ye Tengqi, "Visual Object Detection from Lifelogs using Visual Non-lifelog Data"
COCO¶
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints


Source: Microsoft COCO: Common Objects in Context
COCO json¶
COCO format JSON file consists of five sections providing information for an entire dataset. For more information, see COCO format.
- info – general information about the dataset.
- licenses – license information for the images in the dataset.
- images – a list of images in the dataset.
- annotations – a list of annotations (including bounding boxes) that are present in all images in the dataset.
- categories – a list of label categories.
{
"info": info,
"images": [image],
"annotations": [annotation],
"licenses": [license],
}
info{
"year": int,
"version": str,
"description": str,
"contributor": str,
"url": str,
"date_created": datetime,
}
image{
"id": int,
"width": int,
"height": int,
"file_name": str,
"license": int,
"flickr_url": str,
"coco_url": str,
"date_captured": datetime,
}
license{
"id": int,
"name": str,
"url": str,
}
{
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0","year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
},
"licenses": [
{"url": "http://creativecommons.org/licenses/by/2.0/","id": 4,"name": "Attribution License"}
],
"images": [
{"id": 242287, "license": 4,
"coco_url": "http://images.cocodataset.org/val2017/xxxxxxxxxxxx.jpg",
"flickr_url": "http://farm3.staticflickr.com/2626/xxxxxxxxxxxx.jpg",
"width": 426, "height": 640, "file_name": "xxxxxxxxx.jpg",
"date_captured": "2013-11-15 02:41:42"},
{"id": 245915, "license": 4,
"coco_url": "http://images.cocodataset.org/val2017/nnnnnnnnnnnn.jpg",
"flickr_url": "http://farm1.staticflickr.com/88/xxxxxxxxxxxx.jpg",
"width": 640, "height": 480, "file_name": "nnnnnnnnnn.jpg",
"date_captured": "2013-11-18 02:53:27"}
],
"annotations": [
{"id": 125686, "category_id": 0, "iscrowd": 0,
"segmentation": [[164.81, 417.51,......167.55, 410.64]],
"image_id": 242287, "area": 42061.80340000001,
"bbox": [19.23, 383.18, 314.5, 244.46]},
{"id": 1409619, "category_id": 0, "iscrowd": 0,
"segmentation": [[376.81, 238.8,........382.74, 241.17]],
"image_id": 245915, "area": 3556.2197000000015,
"bbox": [399, 251, 155, 101]},
{"id": 1410165, "category_id": 1, "iscrowd": 0,
"segmentation": [[486.34, 239.01,..........495.95, 244.39]],
"image_id": 245915, "area": 1775.8932499999994,
"bbox": [86, 65, 220, 334]}
],
"categories": [
{"supercategory": "speaker","id": 0,"name": "echo"},
{"supercategory": "speaker","id": 1,"name": "echo dot"}
]
}
Few other datasets...¶
Skin cancer dataset HAM10000¶

Examples of images downloaded from the HAM10000 dataset. These images are publicly available through the International Skin Imaging Collaboration (ISIC) archive and represent more than 95% of all pigmented lesions encountered during clinical practice (Tschandl P 2018). (A) Melanocytic nevus; (B) Bening keratosis; (C) Vascular lesion; (D) Dermatofibroma; (E) Intraepithelial carcinoma; (F) Basal cell carcinoma; (G) Melanoma. Legends inside each image represents clinical data such as age, sex and localization associated to the image. F: female; M: male; LE: lower extremity; B: back; H: Hand; T: trunk.
Annotation tools¶
CVAT¶



Taken from "Deep Learning vs. Traditional Computer Vision"